
Recursive Language Models (RLM): A New Way to Handle Long Contexts
Quick Refresher: How LLMs Work
Before diving into RLM, it helps to understand the basics of how a Large Language Model (LLM) works under the hood.

Modern LLMs like GPT-4 or Claude are built on the Transformer architecture, which processes text through several stages:
- Tokenization splits words into tokens and maps them to IDs using a lookup table
- Embedding converts token IDs into numerical vectors, learned during training
- Transformer Layers are the core model; they use Attention and Feedforward Networks (FFN) to process the vectors
- Output Head converts the final vectors back to token probabilities using Softmax
A few key concepts worth knowing:
- Positional Encoding is math that ensures word order matters (so "man eats cat" ≠ "cat eats man")
- Attention assigns a weight to each token in the context, determining how much it "matters" to the current prediction
- QKV Pattern is the mechanism behind Attention: Q (Query) = "what am I looking for?", K (Key) = "what do I contain?", V (Value) = "what information do I carry?"
- REPL stands for Read-Eval-Print-Loop, the mechanism used by interpreted languages like Python to run code interactively
The Context Window Problem
Context is the entire prompt scope, your full chat history from start to finish, loaded into the model's memory as tokens.
Attention is the weighted relevance of each token within that context.
The critical issue: context windows are finite. Once a conversation grows long enough, earlier messages get pushed out of the model's memory entirely. The model literally forgets what you said at the start. This is called the context length issue.

Testing a model's ability to find specific information within a long context is called the Needle in a Haystack problem, and it gets harder as context length grows.
What is RLM?
"Recursive Language Model or RLM is a general inference strategy where language models can decompose and recursively interact with their input context as a variable." by Alex L. Zhang
RLM is, at its core, a strategy for dealing with long contexts, the same fundamental problem that RAG (Retrieval-Augmented Generation) tries to solve.
The key difference between the two:
- RAG uses "caching", storing information in a vector database and retrieving the most relevant chunks at query time

RAG sequence diagram - RLM uses "algorithm", changing how the model processes the context using a divide-and-conquer approach powered by a REPL environment
RLM sequence diagram
RAG: How it works
- Retrieval converts the user's query into a vector
- Search performs a similarity search (e.g. cosine similarity) to find the most relevant chunks in the vector database
- Injection prepends or appends the retrieved text to the user's prompt as context
- Generation is where the LLM processes the augmented prompt and generates a response
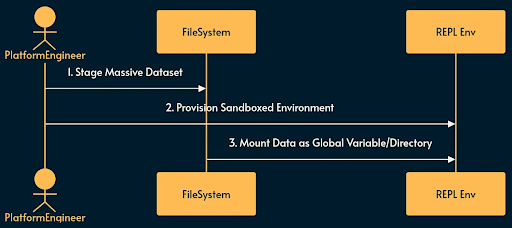
RLM: How it works
- Environment Provisioning sets up a sandboxed REPL environment (e.g. a Docker container or Firecracker microVM) with the necessary runtimes (Python, Node.js, etc.)
- Data Staging places the massive dataset (e.g. an entire code repository or gigabytes of legal documents) on a fast local filesystem
- Variable Mounting loads the dataset into the REPL environment as an accessible global variable or directory structure
How Does RLM Work?
The model operates in a tree structure. The root LM (depth=0) receives the full query and context. When the context is too large to process directly, it generates Python code that runs in a REPL environment to break the problem down further, spinning up child LM instances (depth=1, depth=2, etc.) as needed.

Divide phase: The root language model examines the context and generates Python code to be executed. This code extracts only the useful information for the query. The model then spins up new REPL environments to subdivide the problem further into sub-queries and sub-contexts.
Conquer phase: Once a child instance finds its answer, or has covered its entire portion of the context without truncation, it returns its result back to the calling instance. This bubbles back up through the call stack until the root LM produces the final response.

The Four Operations Available to an RLM
The model has four main tools it can call during execution:
1. Peeking Viewing a truncated version of the context to understand its format, for example reading only the first 2000 characters to understand the structure before deciding how to proceed.

2. Grepping
Performing syntactic or exact-match keyword searches across the full context, similar to running grep on a large codebase to find specific lines matching a pattern.

3. Partition & Mapping Dividing the context into sub-queries using semantic mappings, then running the RLM recursively on each partition. This is the core divide-and-conquer step that allows the model to process datasets far larger than any single context window.

4. Summarization Condensing a long chunk of text into a shorter, targeted summary, extracting only the information relevant to the current query rather than passing the full text upward.
Pros and Cons
Pros: Dramatically Better Performance on Long Contexts
The paper benchmarks RLM(GPT-5) against plain GPT-5 across three tasks:
- OOLONG is a long reasoning benchmark requiring semantic transformation and aggregation of chunks
- OOLONG-Pairs is a modified version of OOLONG with 20 new queries requiring aggregation of pairs of chunks
- S-NIAH consists of 50 single needle-in-a-haystack tasks (finding a specific phrase or number in a large body of unrelated text)

The result is stark: standard GPT-5's performance on OOLONG and OOLONG-Pairs collapses to near zero beyond ~262k tokens. RLM(GPT-5) maintains meaningful scores even at 524k tokens and beyond.
Cons: Speed and Parallelism
Performance overhead is a real cost, since the REPL component actually interprets and executes code in a sandboxed environment. Every step involves generating code, running it, and waiting for the output, which adds latency compared to a direct LLM call.
Blocking by design means that because RLM is recursive, each call in the stack must complete before returning results to its caller. The calls cannot be parallelized; you must wait for each depth level to finish before moving up.
Summary
RLM is a compelling inference strategy for tasks that require reasoning over very large contexts. Think: querying an entire codebase, analyzing gigabytes of legal documents, or searching through a long book. Rather than trying to fit everything into a context window (RAG's approach), RLM treats the context as a variable and algorithmically decomposes the problem into manageable pieces.
The tradeoff is speed: RLM is slower and sequential by nature. But for tasks where accuracy over long contexts matters more than latency, the benchmark results suggest it's a meaningful improvement over simply expanding the context window
REFERENCES
- Recursive Language Models Paper: https://arxiv.org/abs/2512.24601
- Recursive Language Models Blog: https://alexzhang13.github.io/blog/2025/rlm/
- Youtube RLM: https://youtu.be/qznFV59f3Uk